Claude’s Privacy U-Turn: From Commitment to Data Crisis
 Today, we’re discussing something that may affect every Claude user. If you’ve opened Claude recently—whether the free, Pro, or Max version—you’ve probably seen a pop-up. Behind this pop-up is a complete reversal of Anthropic’s previous privacy commitments.
Today, we’re discussing something that may affect every Claude user. If you’ve opened Claude recently—whether the free, Pro, or Max version—you’ve probably seen a pop-up. Behind this pop-up is a complete reversal of Anthropic’s previous privacy commitments.
When Claude first launched, Anthropic clearly stated: “We will never use user data to train our models.” This was a key reason many users chose Claude. But now, not only are they asking users to choose whether to allow their data to be used for training, they’ve set a one-month “final deadline” and extended the data retention period to five years after consent. This has caused an uproar in the tech community abroad. Users have accused Anthropic of “betraying” them and have dug up a series of past actions that have disappointed users. Today, let’s talk about the details of this policy update, real user feedback, and the privacy dilemma facing the entire AI industry.
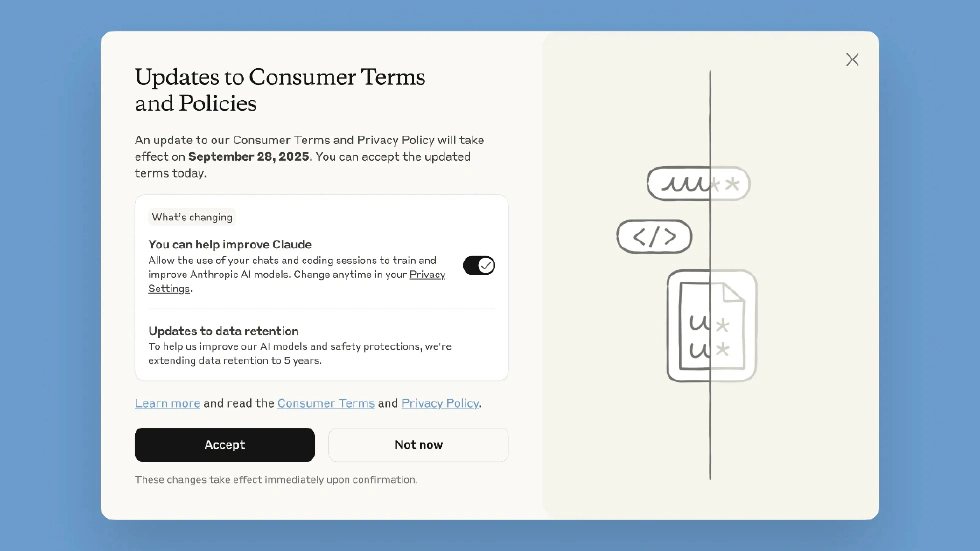
Anthropic’s New Policy: What Has Changed?
First, let’s clarify exactly what Anthropic has changed and what “traps” they’ve set for users. According to Anthropic’s consumer terms update published on their official blog on August 29, 2025, the core of this adjustment is the user’s right to choose whether their data is used for model training. But this so-called choice is full of restrictions.


For existing Claude users, Anthropic has set a deadline of September 28, 2025. If you choose to “accept” data being used for training before this date, then from the moment you click accept, all new or restarted chat sessions, coding sessions, including operations using Claude Code, will be included in training data.
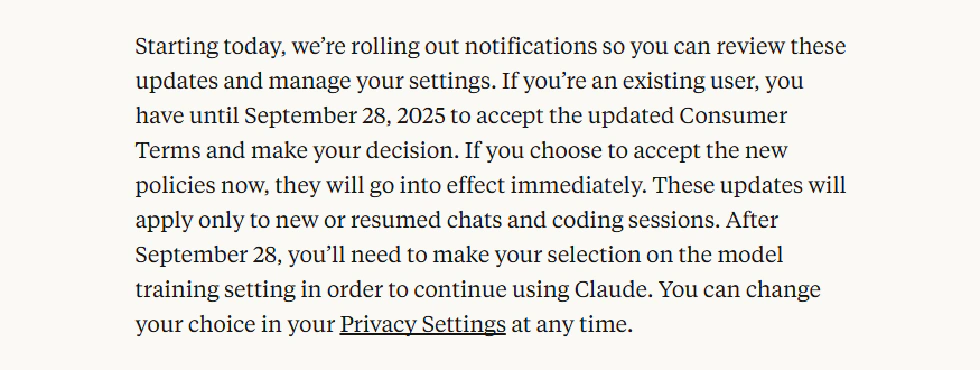
If you haven’t made a choice by September 28, you won’t be able to use Claude until you select your preference in the model training settings. For new users, it’s even more direct: you must make this choice during registration, or you can’t use the service.

Besides the choice mechanism, the change in data retention period is also crucial. If users consent to data being used for training, Anthropic will retain this data for five years. Only if you actively delete a conversation will it not be used for future training. If you do not consent, Anthropic will continue the previous policy: a 30-day retention period.

But it is important to note that: Anthropic has made it clear that this adjustment only applies to “consumer users”—those using the free, Pro, Max, or Claude Code personal versions. Users of the government version (Claude Gov), enterprise version (Claude for Work), education version (Claude for Education), or commercial customers accessing via API are not affected. In other words, Anthropic has made a clear distinction between personal and business users’ privacy, with business customers’ privacy seemingly more “valued,” while personal users become potential “contributors” to training data.

The Real Reason Behind the Change
You might ask: Why is Anthropic doing this? Their blog gives seemingly “noble” reasons: if users consent to data being used for training, it can help improve model safety, make harmful content detection more accurate, reduce false positives, and enhance Claude’s future coding, analysis, and reasoning abilities—ultimately benefiting all users.

But anyone familiar with the AI industry knows the real reason is “data anxiety.” The competition between large models is essentially a competition for data. Only by obtaining more real user interaction data can models surpass competitors in core capabilities like reasoning and coding.
As a direct competitor to OpenAI and Google, Anthropic needs massive user data to close the gap. Consumer users’ conversations and coding records are a “gold mine” closest to real usage scenarios. So, this policy change is less about giving users choice and more about forcing them to answer Anthropic’s “must-answer question” to obtain training data. Users’ anger stems from this: a supposed choice that is actually a forced consent, especially in the interface design.
Interface Design: Guiding Users to Consent
Many users report that the Claude policy update pop-up is highly suggestive. The title is a large, bold “Consumer Terms and Policy Update,” with a prominent black “Accept” button taking up half the screen. The crucial “Consent to data for training” option is hidden in small text below the “Accept” button, and the toggle is set to “on” by default. What does this mean? It’s like those old software installers with default “agree to install all bundled software” options. Most users will habitually click “Accept,” not realizing they’ve just agreed to let Anthropic use their data for five years. Some users joke: this isn’t a choice, it’s a “trap,” and Anthropic is treating users like fools.
Anthropic’s History of “Betraying” Users
What’s even more unacceptable is that this policy reversal isn’t Anthropic’s first “betrayal.” A user named Ahmad detailed in a tweet a series of controversial actions by Anthropic since Claude’s launch, each hitting users’ pain points.
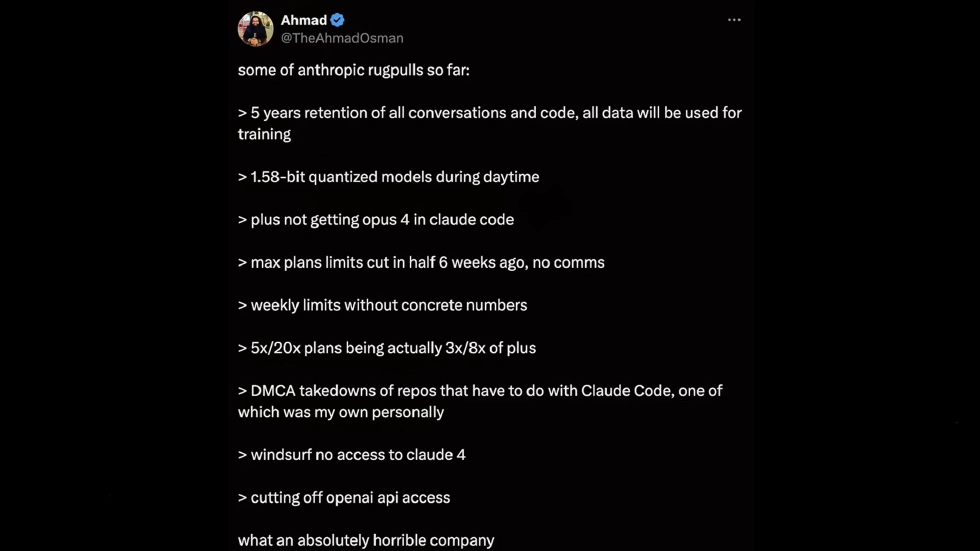
For example, besides the new five-year data retention and training, Ahmad says Anthropic quietly switches users to a 1.58-bit quantized model during the day, reducing parameter precision to save computing power—at the cost of lower reasoning accuracy and response quality, all without user knowledge. Users pay for the full version but get a downgraded service.
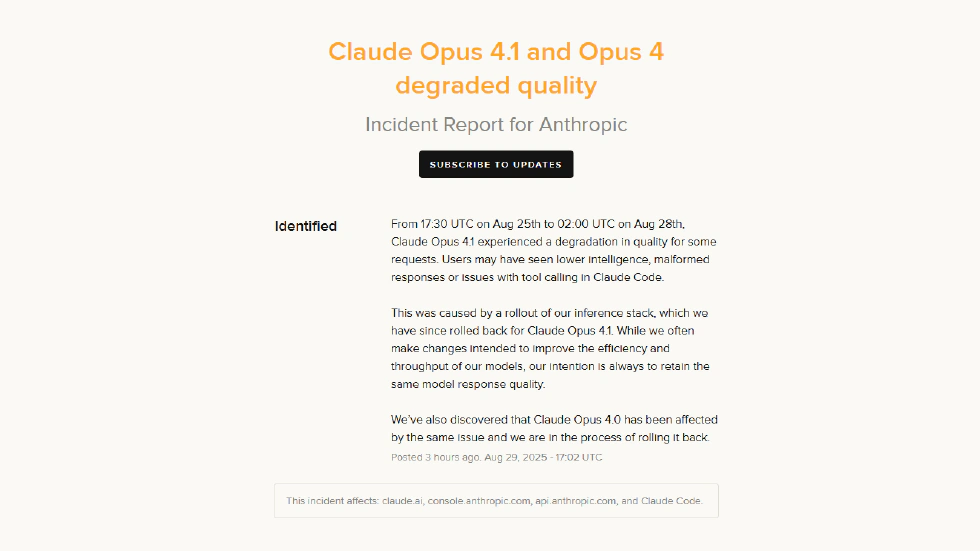
Plus members, who pay for better service, can’t use Anthropic’s strongest Opus 4 model in Claude Code—like paying for a half-finished product. Even more outrageous: six weeks ago, Anthropic halved the Max plan’s usage limit without notice. The Max plan is much pricier than Plus, and many users bought it for the “high usage.” Suddenly, the quota is cut with no explanation. Plus and Max plans have never publicly disclosed weekly usage limits; users only find out when they hit the cap.
The “5x usage plan” and “20x usage plan” are also misleading: actual usage is less than half the advertised amount. Users calculated that the “5x plan” only gives 3x the Plus plan, and the “20x plan” only 8x—clear false advertising.
DMCA Takedowns and Other Controversial Actions
Ahmad also mentioned his project was taken down due to Anthropic’s indiscriminate DMCA (Digital Millennium Copyright Act) notices, even though his project didn’t infringe. This “one-size-fits-all” DMCA approach directly impacts developers’ work.
Other actions include banning Windsurf users from using Claude 4 and cutting off access to the OpenAI API. Each of these shows Anthropic’s lack of respect for users, so it’s no wonder this policy reversal has sparked such anger.


The Industry-Wide Data Grab
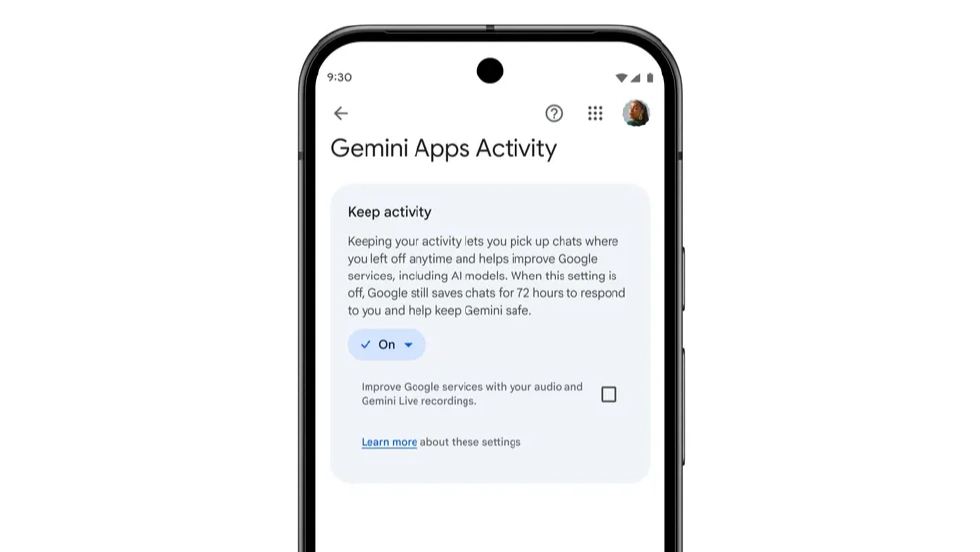
In fact, Anthropic’s actions aren’t unique in the AI industry. The entire large model sector is competing for “user data,” with many big companies quietly adjusting privacy policies to obtain more training data. For example, Google recently renamed Gemini’s “Gemini Apps Activity” to “Keep Activity,” and from September 2, 2025, any enabled activity may be used to improve Google services for everyone—essentially the same logic as Anthropic’s data-for-training, just worded differently.
OpenAI, due to the New York Times copyright lawsuit, recently admitted for the first time that since mid-May 2025, they’ve been quietly saving users’ deleted chat records and temporary sessions. Many users were shocked: “So my deleted ChatGPT conversations weren’t really deleted, but archived by OpenAI? Isn’t this a privacy violation?” OpenAI claims it’s for litigation needs, but this “post-hoc notification” erodes user trust in privacy protection.
Why User Data Is So Valuable
Why are these big companies so obsessed with user data? Because for large models, real user interaction data is a “must-have.” No matter how rich lab training data is, it can’t compare to real user prompts, conversations, and coding needs. This data helps models better understand user needs—coding that matches developers’ habits, analysis that fits users’ logic, and even reduces nonsense. So, to gain an edge over competitors, companies risk losing user trust to adjust policies and obtain data.
But the core issue is: who protects user privacy? When adjusting policies, these companies often use phrases like “improving service quality” and “optimizing model experience,” but deliberately downplay details about data usage and protection. For example, Anthropic says deleted conversations won’t be used for training, but doesn’t say whether data already used for training will be deleted. They say “retained for five years,” but don’t specify what happens after five years—complete deletion or some other form of retention? These vague statements leave users unable to judge if their privacy is truly protected.
More importantly, most users don’t have the time or energy to read lengthy privacy policies—thousands or even tens of thousands of words full of jargon. Ordinary people can’t understand them, and companies exploit this by hiding key privacy terms in dense text or using interface design to guide users to “default consent.” In this situation, users’ “choice” is essentially meaningless—they don’t know what they’re agreeing to or the consequences.

From a regulatory perspective, oversight of AI companies’ data use is still lagging. While there are data protection laws like the EU’s GDPR and California’s CCPA, these often fall short when facing large model data needs. For example, GDPR requires explicit user consent, but is Anthropic’s default-on plus interface guidance really explicit consent? There’s no unified standard, giving companies room to exploit loopholes.
The Fundamental Contradiction in AI
Back to Anthropic’s incident: it reflects a fundamental contradiction in the AI industry. On one hand, large models need user data to improve; on the other, users worry about privacy violations. How to balance these is a problem every AI company must face—not force users to compromise through tricks. For example, Anthropic could make “Consent to data for training” a more prominent option, use plain language to explain how data will be used and retained, and the impact of not consenting, instead of hiding it in small print.
They could also make data usage processes public, allowing users to check if and when their data was used for training. Only transparency can rebuild user trust.
What Users Should Do Now
Finally, a reminder to all Claude users: if you haven’t dealt with this policy update, be sure to open Claude’s “Model Training Settings” before September 28, carefully check the “Consent to data for training” option, and make a choice based on your privacy needs—don’t just habitually click “Accept.” If you don’t use Claude, take a few minutes to check the privacy policy when choosing other AI tools, focusing on “Is data used for training?”, “How long is data retained?”, and “Can you withdraw consent at any time?” After all, every conversation and every piece of code is your personal information and shouldn’t be “contributed” lightly.
Conclusion
For AI companies like Anthropic, I hope they understand: user trust is the most valuable asset. Without trust, even the strongest technology won’t go far. If you truly need user data to improve your model, communicate honestly and offer reasonable compensation—instead of using “ultimatums” and “interface tricks” to force users. That’s what a responsible tech company should do.
Anthropic’s policy reversal is a wake-up call for all AI users and companies. As users, we must be vigilant about our privacy choices and demand transparency. As companies, respecting user trust and privacy is not just ethical—it’s essential for long-term success. Only with openness and respect can the AI industry move forward in a way that benefits everyone.
References
- Updates to Consumer Terms and Privacy Policy Anthropic. 2025-08-29.
- TheAhmadOsman X (Twitter). 2025-08-29.
- Anthropic just rug-pulled Claude Max users — here’s the proof Reddit. 2025-07-28
- Judge rejects Anthropic bid to appeal copyright ruling, postpone trial Reuters. 2025-08-12.
- Statement on Anthropic Model Availability Windsurf. 2025-06-03.
- Anthropic Revokes OpenAI’s Access to Claude WIRED. 2025-08-01.
- OpenAI slams court order to save all ChatGPT logs, including deleted chats Ars Technica. 2025-06-05.