Context Engineering: The Key to Reliable AI Agents
 Have you ever felt that today’s AI agents seem technically advanced, but often disappoint in real-world use? Maybe they give up halfway when handling complex tasks. You might think, “Is the model not strong enough?” But industry experts have observed that most AI agent failures aren’t due to model limitations—they’re failures of context engineering.
Have you ever felt that today’s AI agents seem technically advanced, but often disappoint in real-world use? Maybe they give up halfway when handling complex tasks. You might think, “Is the model not strong enough?” But industry experts have observed that most AI agent failures aren’t due to model limitations—they’re failures of context engineering.
So, what is “Context Engineering”? How does it relate to familiar concepts like prompt engineering, Retrieval-Augmented Generation (RAG), and Model Context Protocol (MCP)? Let’s break it down.
What Is Context?
Many people think context is just chat history. That’s only part of the story. At its core, context is the complete set of information provided to a large language model (LLM) to help it reason or generate the next output. This definition is simple, but the content is richer than you might expect.
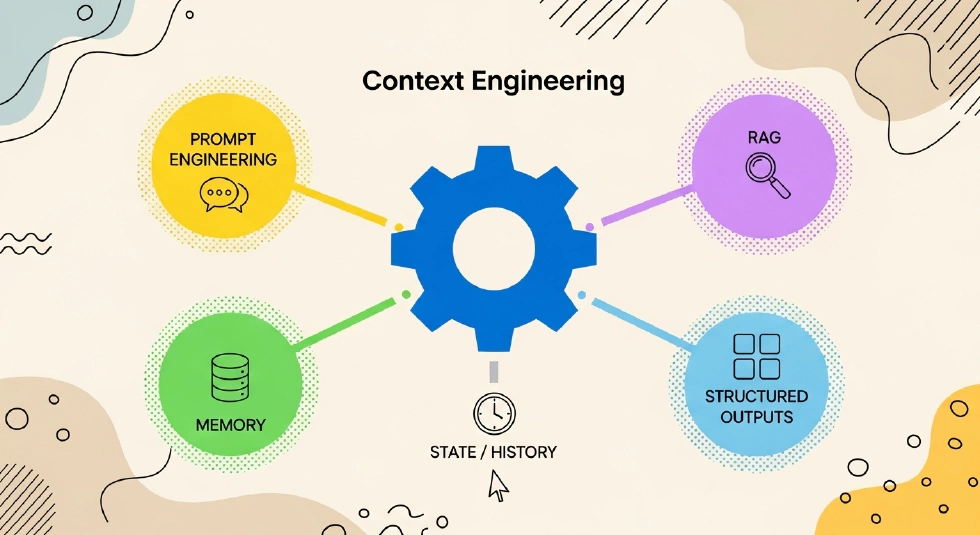
Context is not just a single thing. It can be guiding, informational, or actionable. Guiding context tells the model what to do and how to do it, setting the framework, goals, and rules for its behavior. This is where prompt engineering comes in, optimizing system prompts, task descriptions, examples, and output formats. Informational context provides the model with the knowledge it needs—facts, data, and essential information. RAG and memory systems, whether short-term or long-term, are part of this. Actionable context enables the model to interact with the outside world, including tool definitions, tool calls, and results.
So, context is a multi-dimensional, dynamic, task-oriented system—not just a chat log.
What Is Context Engineering?
AI leaders Tobi Lütke and Andrej Karpathy describe context engineering as the art and science of providing all necessary context so LLMs can solve tasks effectively. It’s about designing, building, and maintaining a dynamic system that intelligently assembles the optimal context for every step of an agent’s task.
Karpathy likens agents to operating systems: the model is the CPU, the context window is memory, and context engineering is the memory manager, deciding what data to load, swap, and prioritize for smooth operation and accurate results. This marks an upgrade in how we interact with LLMs—from optimizing prompts to building efficient information supply systems.

How Is Context Engineering Different from Prompt Engineering and RAG?
They’re not mutually exclusive; they operate at different layers and collaborate. Prompt engineering optimizes instructions for single interactions—defining roles, adding examples, and output formats. It’s fine-grained and single-turn. RAG retrieves relevant information from external knowledge bases, filling the informational context. Context engineering encompasses both, plus dynamically combines all context types, manages failures, and ensures robust task completion.
Why Do We Need Context Engineering?
When agent outputs fall short, it’s usually due to missing context, not model weakness. As base models get smarter, context engineering becomes the main bottleneck. Without it, models make uncertain guesses or hallucinate.
Imagine your AI assistant receives a simple email: “Hi, are you free to meet tomorrow?” A context-poor agent replies mechanically: “Thanks for your message. I’m free tomorrow. What time works for you?” But a context-rich agent checks your calendar (you’re busy), recognizes the sender (Jim, an important partner), analyzes past emails (informal tone), and offers to send a calendar invite. The response is: “Hi Jim! I’m fully booked tomorrow, but free Thursday morning. I’ve sent a tentative invite—let me know if that works!” The magic isn’t a smarter model, but a system that dynamically assembles the right context.
Suppose an agent is tasked with building a new feature in a large codebase over several days. A naive strategy is to record every interaction and feed the entire history to the model each time. This leads to performance drops, cost and delay spikes, and context overflow. Context engineering solves this by intelligently managing and compressing context, injecting only high-value information.
The Four Pillars of Context Engineering
Context engineering involves four key strategies: write, select, compress, and isolate.
Writing means persisting context beyond the window limit for future use. This can be temporary scratchpads for current tasks or long-term memory for cross-session learning. Selecting is about dynamically pulling the most relevant info for each subtask, whether by preset rules, model-driven filtering, or similarity search from memory or external sources. Compressing reduces information to fit the context window, keeping only the core signals, often through auto-compression or pruning. Isolating is an architectural strategy, setting boundaries between information streams. Sub-agents digest raw info and submit key insights to the main agent, reducing cognitive load and increasing information density.
Compression boosts density in a single stream, while isolation manages complexity across streams. Mature systems use both.

Model Context Protocol (MCP): The Infrastructure
MCP is a standardized interface for tool and data interaction—especially for actionable and informational context. It enables agents to communicate smoothly and securely with external tools and data sources, forming the backbone of robust context engineering.
Conclusion
Most AI agent failures aren’t about model capability—they’re about context engineering. Whether it’s prompt engineering, RAG, or MCP, the goal is the same: prepare the right context before the model makes a decision.
Mastering write, select, compress, and isolate is the key to building reliable, scalable AI systems. The focus is shifting from crafting perfect prompts to designing systems that dynamically assemble perfect context at every step.